
حاسوبي الذي يرى (الجزء الثاني)
تحدثنا في المقال السابق عن مصطلح الرؤية الحاسوبية وما يعنيه، وعن طريقة عمل تلك الآلية بشكل مبسط، ومناظرتها لحاسة الإبصار لدى البشر، كما ناقشنا بعض أهم تطبيقات واستخدامات هذا المجال دائمة التطور في عالمنا المعاصر.
أما اليوم، فنتحدث عن شيء مختلف، حيث نأخذ خطوة للوراء لنرى تاريخًا موجزًا لهذا المجال سريع الاستحداث، ولنشهد بداياته الأولى ومولده ثم عنفوان انطلاقته، لعلنا نضع سياقًا لما بين يدينا اليوم من تقنية.
بداية الموضوع مع القطط
خلال خمسينيات وستينيات القرن الماضي، أجرى العالمان «هيوبل وويزيل» (Hubel and Wiesel) سلسلة من الاختبارات على أدمغة القطط عند عرض بعض الصور عليها، بهدف معرفة أي الخلايا بعينها التي تنشط عند عرض بعض الأشكال، ليكتشفا أن جهاز الرؤية الطبيعي يسير وفق خطوات محددة ومتتالية لفهم الصورة المعروضة أمامه. المخ في البشر (كما في القطط) يحوي أعصابًا تنشط عند رؤية أشكال كالخطوط مثلًا، وعند نشاطها تقوم هذه الأعصاب بتنشيط ما يليها من خلايا أخرى مسؤولة عن أشكال أخرى كالحواف، وهكذا يزداد الترتيب التصاعدي لتعقيد الأشكال المُدرَكة والخلايا المسؤولة عنها.
وبناء عليه، قرر مهندسو البرمجيات بناء أنظمة الرؤية الحاسوبية على نفس النمط، وبنفس الترتيب الهرمي للرؤية الطبيعية.

لاري روبرتس وأُبُوَّة الرؤية الحاسوبية
إلى جانب كونه أحد مؤسسي الشبكة العنكبوتية التي تستخدمها الآن لقراءة هذا المقال، «لاري روبرتس» (Larry Roberts) معروف أيضًا بأنه أهم من أسهم في مجال الرؤية الحاسوبية؛ ففي عام 1963 أصدر لاري روبرتس ورقته البحثية لحصوله على درجة الدكتوراة من معهد ماساتشوستس، وعاد فيها لمفهوم هيوبل وويزيل عن الإدراك الهرمي للرؤية، فوصف برنامجًا للرؤية الحاسوبية يعمل على استخلاص معلومات ثلاثية الأبعاد عن الأشكال المُصمَتة ثنائية الأبعاد، معتمدًا على تتبع الخطوط والحواف التي تكوّن هذه الأشكال. كان نجاح روبرتس وقتها سابقًا لزمانه ولإمكانيات الحواسيب في عصره.
مشروع الرؤية الصيفي
استمرت المحاولات خلال الستينيات للوصول لآلة قادرة على الرؤية، فكانت توقيتًا لأول محاولة حقيقية لتوصيل جهاز كاميرا بحاسوب وجعله يرى العالم. وكان هدف المشروع هو جعل الحاسوب يُفرِّق بين الخلفية والأجسام في الصور، ويحدد بشكل دقيق ماهية هذه الأجسام التي يراها.
على الرغم من أن محاولات الطلاب في المشروع الصيفي للرؤية والمنعقد في يوليو عام 1966 لم تَنُم عن أي نتائج تُذكَر، فإن كثيرًا ما يشار إلى المشروع الصيفي على أنه الانطلاقة الحقيقية لدراسة مجال الرؤية الحاسوبية كونه مجالًا أكاديميًا. لعل هؤلاء الطلاب خاليو النتائج لم يعرفوا أن ما بدأوه كمشروع صيفي طَموح سيأخذ عقودًا من العمل للوصول لنجاح حقيقي بنتائج مُرضية.

اليابان تقدم لنا شبكة الـ«نيوكوجنترون» (Neocognitron)
في العام 1979 يعود بنا العالم «كونيهيكو فوكوشيما» (Kunihiko Fukushima) إلى تحليل الخطوط مرة أخرى، بعد أن أُثبت مغالاة طموح الرؤية الفورية مع قدرة الحواسيب وقتها.
وينجح في تقديم نموذج قادر على معرفة وقراءة الأحرف المطبوعة أو المكتوبة بخط اليد، بل ويكوّن النواة لأول شبكة عصبية قادرة على التعلم بذاتها بدون الحاجة إلى رقابة.
يعود فوكوشيما في نموذجه للرؤية لنظرية هيوبل وويزيل عن الرؤية في الإنسان، ويتكون نموذجه من مستويات مختلفة التعقيد، يحوي المستوى الأول فيها على مجموعات من «الخلايا البسيطة» (Simple Cells, S-Cells) القادرة على إدراك الأشكال الأقل تعقيدًا. يليه المستوى التالي الذي يحوي «خلايا معقدة» (Complex Cells, C-Cells) لإدراك الأشكال الأعقد.
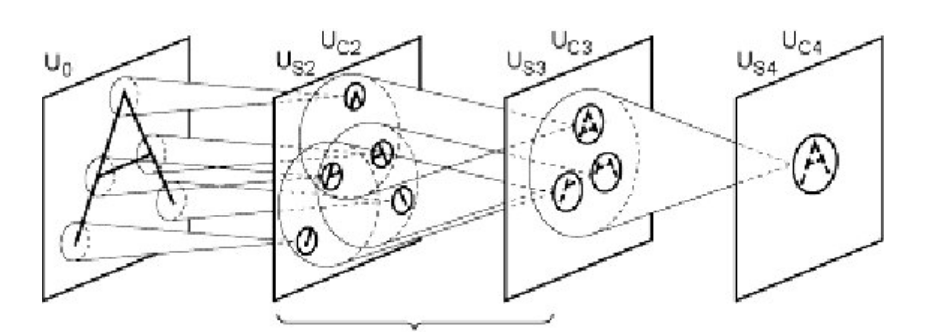
Source: Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position
ثورة الشبكات العصبية الالتفافية
في محاولات دامت من ثمانينيات إلى تسعينيات القرن الماضي، تمكن المجتمع العلمي من إدخال مفهوم الشبكات والبرامج آلية التعلم في مجال الرؤية الحاسوبية. تُمثِّل محاولات العالم «يان ليكون» (Yann LeCun) عام 1980 في استخدام الشبكات العصبية ودمجها مع مجال الرؤية الحاسوبية، البداية الحقيقية للاعتماد على الشبكات العصبية الالتفافية، الاعتماد الذي ما يزال قائمًا حتى اليوم في أحدث تقنيات الرؤية الحاسوبية.
تتكون الشبكات العصبية الالتفافية كما شرحنا في المقال السابق (راجِع مقال: الرؤية الحاسوبية – الجزء الأول) من مستويات متدرجة في تعقيد استقبال الصور، حيث تُعنى خلايا كل مستوى بخاصية محددة تستخرجها من الصور، وتسير هذه الخواص من الأسهل للأعقد؛ في المستويات الأولى يتم استقبال أشياء أولية كالخطوط والحواف، ثم تتدرج المستويات في التعقيد حتى نصل لمستويات معنية بإدراك أشياء محددة كالوجوه والأشخاص.
2001- خوارزمية فايولا جونز للتعرف على الوجوه
نجح العالمان «بول فيولا» (Paul Viola) و«مايكل جونز» (Michael Jones) في تطوير أول نظام تعرف على الوجوه. يقوم نظامهما بالتدريب على مجموعات من الوجوه أولًا، ومن ثم، حين يتم إدخال صورة للبرنامج، يقوم بتقسيمها إلى أقسام صغيرة، ويبحث في كلٍ من تلك الأقسام على الملامح التي يعرفها (من التدريب) والتي تميز الوجوه عن غيرها من الأشكال.

Source: Improved Viola-Jones face detection algorithm based on HoloLens
مولد أعظم قاعدة بيانات للصور
التحديث العظيم في الأنظمة والنماذج يحتاج بالتبعية تحديثًا لقواعد البيانات الضرورية لتلك الأنظمة. قاعدة البيانات هذه هي ما كانت ينقص مجال الرؤية الحاسوبية حتى العام 2006، عندما قامت البروفيسورة «في في لي» (Fei-Fei li) من جامعة ستانفورد بقيادة فريق لبناء أول وأهم قاعدة بيانات للصور، وتحتوي قاعدة بيانات (ImageNet) اليوم على ما يزيد عن 14 مليون صورة وتمثل أهم مصدر لتدريب نماذج الرؤية الحاسوبية حتى يومنا.
قفزة AlexNet
بين عامي 2010 و2017، انعقدت مسابقة “تحدي التعرف البصري واسع النطاق” (The ImageNet Large Scale Visual Recognition Challenge) التي تقيمها قاعدة بيانات (ImageNet) بهدف اكتشاف أفضل نموذج مقترَح لحل بعض المشكلات في مجال الرؤية الحاسوبية، مثل تحديد الأجسام ووصف الصور وغيرها.
في العامين الأولين للمسابقة، كان عامل الخطأ في النماذج المتقدمة للمسابقة لا يقل عن 25%، وتغيَّر هذا الأمر في عام 2012 مع نموذج (AlexNet) الذي أعاد استخدام الشبكات العصبية الالتفافية، وأحرز نسبة خطأ تُقدَّر بـ16.4% وهو ما اعتُبِر أمرًا ثوريًا وتكنولوجيا تَعِد بتطور منقطع النظير في مجال الرؤية الحاسوبية. حقق نموذج (AlexNet) هذا النجاح باعتماده على شبكة التفافية مكونة من 8 مستويات فقط، وكانت كافية للتغلب على مثيلاتها من برامج الرؤية
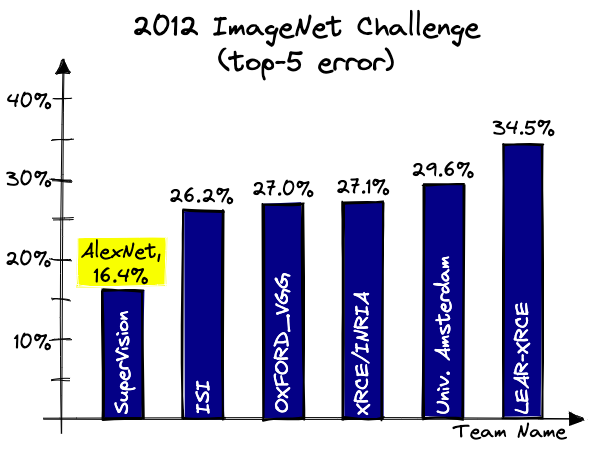
Source: https://www.pinecone.io/learn/series/image-search/imagenet/
حاضر ومستقبل الرؤية الحاسوبية
منذ الثورة التي أحدثها نموذج (AlexNet) اتجهت أنظار العالم مرة أخرى إلى مجال الرؤية الحاسوبية وإمداده بالتمويل اللازم، واستمر العمل على الشبكات الالتفافية وتطويرها وتغذيتها ببيانات أكثر، وكلما زادت أعداد البيانات كلما تحسنت النتيجة. اليوم يتداخل مجال الذكاء الاصطناعي بقوة مع مجال الرؤية الحاسوبية فلا تستطيع فصلهما عن بعضهما، تتعلم النماذج الحالية طرق التعرف على الصور عن طريق «التعلم العميق» (Deep Learning) والتعلم الذاتي بدون رقابة، حيث تتعلم الآلة وحدها عن الصور وماتعنيه، لتجد بنفسها الآلية والأنماط التي ستستخدمها فيما بعد للتعرف على تلك الصور أو مثيلاتها.
وُجِد أيضًا أنه عند دمج مجالي الرؤية الحاسوبية و«معالجة اللغات الطبيعية» (Natural Language Processing, NLP)، فإن النتائج التي نحصل عليها للصور المعنوَنة تكون أفضل وأسرع، وحيث إن من أهم متطلبات برامج الرؤية الحاسوبية -لإعطاء نتائج مقبولة- وجود قاعدة بيانات كبيرة وعالية الدقة للتدريب عليها.
وجد المبرمجون أن إحدى الطرق للتغلب على هذه العقبة هي تصميم برامج تتعلم عن الصور والبيانات البصرية من خلال بيانات نصية إلى جانب البيانات البصرية المعتادة.
اليوم، يظن المرء أن تكنولوجيا الرؤية الحاسوبية قد بلغت أقصاها من التطوير، بيد أن ما ينتظر هذه التقنية من ولوج أماكن لم تكن في خيالاتنا حتى، لم يفتأ أن يبدأ. فاستخدامات تقنية الرؤية الحاسوبية تنتقل اليوم من عالمنا الحقيقي إلى عالم افتراضي، وآخر هجين بين ما هو افتراضي وما هو حقيقي. ويبدو أنه لا يمكن توقُّع خط نهاية للتكنولوجيا وأن كل تطور يمهد فقط للتطور الذي يليه.
المصادر:
حاسوبي الذي يرى (الجزء الأول) | مكتبة علماء مصر (egyptscholars.org)
https://hub.jhu.edu/2015/07/14/golden-goose-award-wiesel-hubel/
https://www.researchgate.net/publication/220695992_Machine_Perception_of_Three-Dimensional_Solids
https://www.image-net.org/index.php
https://www.pinecone.io/learn/series/image-search/imagenet/
http://proceedings.mlr.press/v139/radford21a/radford21a.pdf https://link.springer.com/chapter/10.1007/978-981-99-0369-6_7



